Kalshi Arb Trading
Detect the event, beat the order book: a net-profitable low-latency trading system on a regulated exchange.
- 17.4%
- ROI, net of fees
- ~5,000
- live trades
- 93 days
- live trading window
- sub-35ms
- detect-to-execute
- 719
- per-trade audit reports
01 / The bet: beating the book by milliseconds
The edge is execution speed, not market prediction.
Kalshi is a U.S. CFTC-regulated prediction-market exchange where binary contracts trade on real-world outcomes — including live sports: will the home team win this match? When a goal is scored, the fair value of that contract jumps almost instantly, but the order book takes tens to hundreds of milliseconds to catch up. That lag is the entire opportunity. See the event and get an order in before the book moves, and you buy at a stale price for a contract that is already worth more. It's the same category of edge as latency arbitrage in traditional electronic markets, transplanted to a younger, less efficient venue. The whole project reduces to one question: how often can I land inside that window? I built the system to answer it, then ran it live with real money for 93 days.
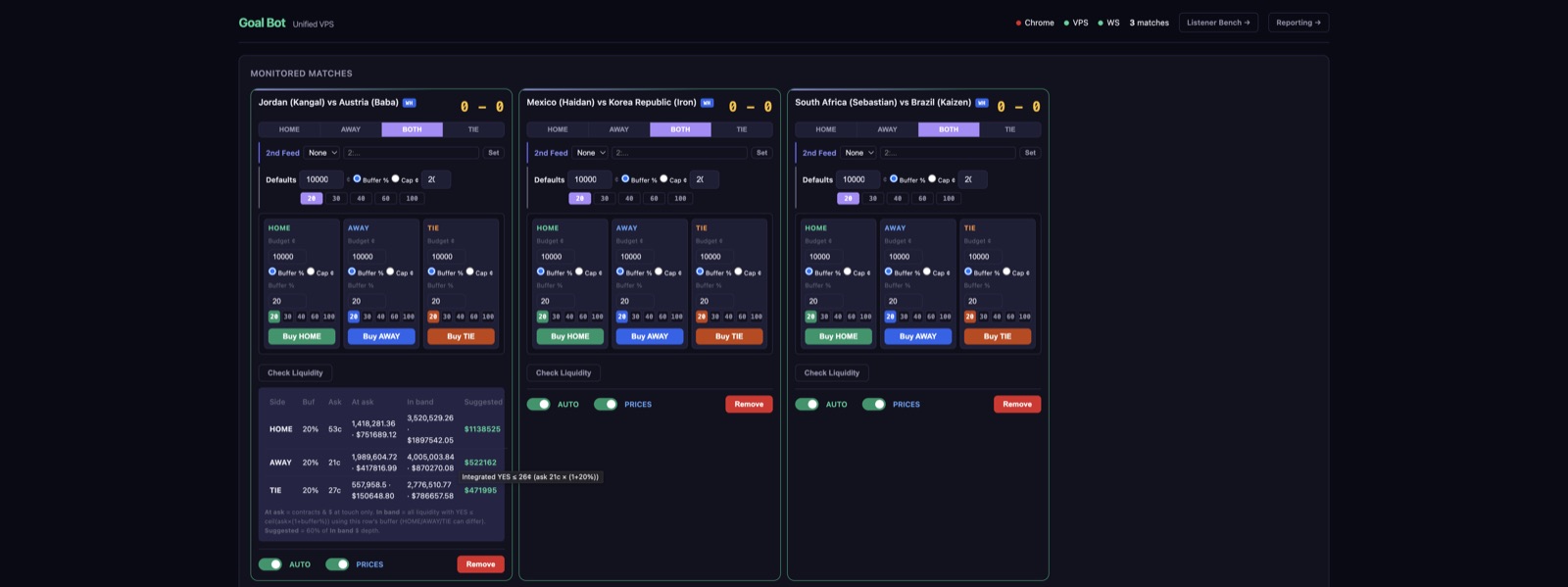
02 / What I built: an operation, not a script
Roughly 45,000 lines of TypeScript across two engines.
The system is roughly 45,000 lines of TypeScript and JavaScript in two engines. The first is a goal-detection bot: five independent real-time sports data feeds — raw WebSocket, SignalR delta streams, push-streaming SDKs, and an HTTP-poll fallback — normalize into a single event stream and run as a race. Whichever feed reports the score change first wins; the others are debounced for 10–15 seconds so the same goal never trades twice. The second is a same-market arbitrage engine that detects when the YES and NO sides of a market can be bought together for less than the $1 settlement after fees, verifies the book over REST, and fires both legs — across soccer, tennis, basketball, baseball, cricket, and esports. Around them sit a real-time dashboard, event-driven risk controls (including a goal-review/VAR handler that liquidates instantly on a reversed call), ~221 Jest tests, and an auto-generated audit report for every trade.
03 / The 35-millisecond execution path
Detection and execution are co-located in one process on a single VPS.
"I saw the goal" and "I'm sending the order" are an in-process event roughly a millisecond apart. An earlier architecture split detector and executor across machines and paid ~100ms for it; co-location deleted that hop. From there the optimizations get surgical: the exchange's RSA-PSS auth signature is regenerated on a background timer so cryptography never sits on the order's critical path; a pre-warmed keep-alive TLS connection means no per-order handshake; all logging is deferred until after the order response so synchronous I/O can't block the send; and a background loop pre-polls prices so the hot path needs no extra GET. End to end, the system runs at ~30–35ms from feed frame to order accepted — about 28ms of which is the unavoidable network round-trip to the exchange. Orders are immediate-or-cancel limits behind per-market budgets, price gates, and a timed auto-sell exit.
04 / Hardest problem #1: five feeds, zero documentation
None of the five data sources ships a clean public API.
Getting five independent live streams to deliver score changes reliably — and fast — into one normalized format meant working at the protocol level: reverse-engineering wire formats, handling each feed's authentication quirks, and patching a streaming SDK to get past a CDN gatekeeper. The trading logic was the easy half; the hard half was making the ingestion layer run untouched for weeks. Stale-frame detection watches every feed, and anything quiet for more than 30 seconds triggers an automatic reconnect, so an overnight provider outage degrades the race instead of killing the system. The racing design is also the reliability story: with five feeds competing to report each event, a single slow or dead source costs latency on some events rather than coverage of any. That redundancy is what let the system trade unattended on a New Jersey VPS under systemd, week after week.
05 / Hardest problem #2: knowing what to optimize
Latency work is seductive — everything feels worth optimizing.
Rather than guess, I built a trade-replay engine: it takes every real trade, including the ones that cancelled unfilled, and re-simulates them against the historical order book at different assumed latencies. That turned a vague instinct ("faster is better") into a measured curve. The replay analysis showed a 30ms speed-up would push the IOC fill rate from ~50% toward ~75% and multiply P&L roughly 1.6× — which meant every optimization had a quantified payoff before I built it. That's how the connection pre-warming and request pre-signing earned their place on the roadmap, and why other ideas didn't. It also produced the most honest number in the project: the median order arrived about 30ms behind the first mover on a given event. The system wasn't winning every race; it was winning enough of them — and I knew exactly which, and why.
06 / The outcome: profitable, and provable
Over a 93-day live window: net profitable, 17.4% ROI across 4,994 trades.
Over a 93-day live window (Jan 25 – Apr 29, 2026) the system ran with real money on the exchange and finished net profitable: a 17.4% ROI, net of fees, across 4,994 trades. In the most closely measured 49-day stretch it hit a 67% win rate, with 368 detected events producing 184 fills — a ~50% IOC fill rate that matches the replay model. The ground truth is the exchange's own account statement, and beneath it sits a 719-file audit trail: one auto-generated report per detected event, with the full timestamp chain, the order, the fill, and an order-book snapshot at that instant. The honest fine print: those figures are that specific window, not annualized, and the edge was strongest in lower-liquidity markets — the most liquid ones had faster competitors, and a handful of net-negative markets were flagged for disabling.
07 / What it proves
The edge is perishable; the engineering disciplines underneath it are what last.
The edge itself is perishable — it's speed, which has to be re-won on every event against competitors who are also getting faster. What lasts are the engineering disciplines underneath it: building reliable real-time pipelines out of messy, undocumented sources; squeezing latency out of a full request path, down to the cryptography and the TCP connection; measuring before optimizing, so engineering effort maps to outcomes; and shipping a complete system — ingestion, execution, risk controls, dashboard, audit trail — that ran unattended and handled real money without losing track of a single transaction. Roughly half my orders still cancelled because I arrived too late, and I can tell you that precisely because the system audits itself. That combination — low-latency systems engineering plus a verified, honestly framed financial result — is what I'd bring to any latency-sensitive or data-intensive build. Stack: TypeScript (strict), Node.js, Jest. Code available on request.
08 / Why I stopped: losing the race I'd been winning
Latency arbitrage is king-of-the-hill.
For 93 days I was at or near the fastest reaction in my markets, and the system was steadily profitable. Then someone faster arrived — another bot started landing orders ahead of mine, consistently inside my detect-to-execute window. In a speed race, second place doesn't earn a little less; it earns nothing. Once my fills started arriving after the book had repriced, the remaining edge couldn't clear fees and adverse selection, so I shut the system down rather than let it bleed into noise. That's the honest lifecycle of a latency edge: it works until somebody outbuilds you. Knowing when it died — because every trade was measured — and having the discipline to stop is as much a part of this system as the sub-35ms path itself.
09 / The system, end to end
Five racing feeds collapse to one event, a sizing engine fires pre-signed IOC orders, and every trade audits itself.
Need a latency-sensitive or real-time data system built and proven? Code walkthrough available on request — get in touch.