Quant Research Platform
I built a trading research platform good enough to prove it shouldn't trade.
- 10+
- automated data feeds
- ~1,290
- automated tests
- ~90%
- calibrated coverage
- 170k+
- lines of code
- $0
- risked — by design
01 / The bet
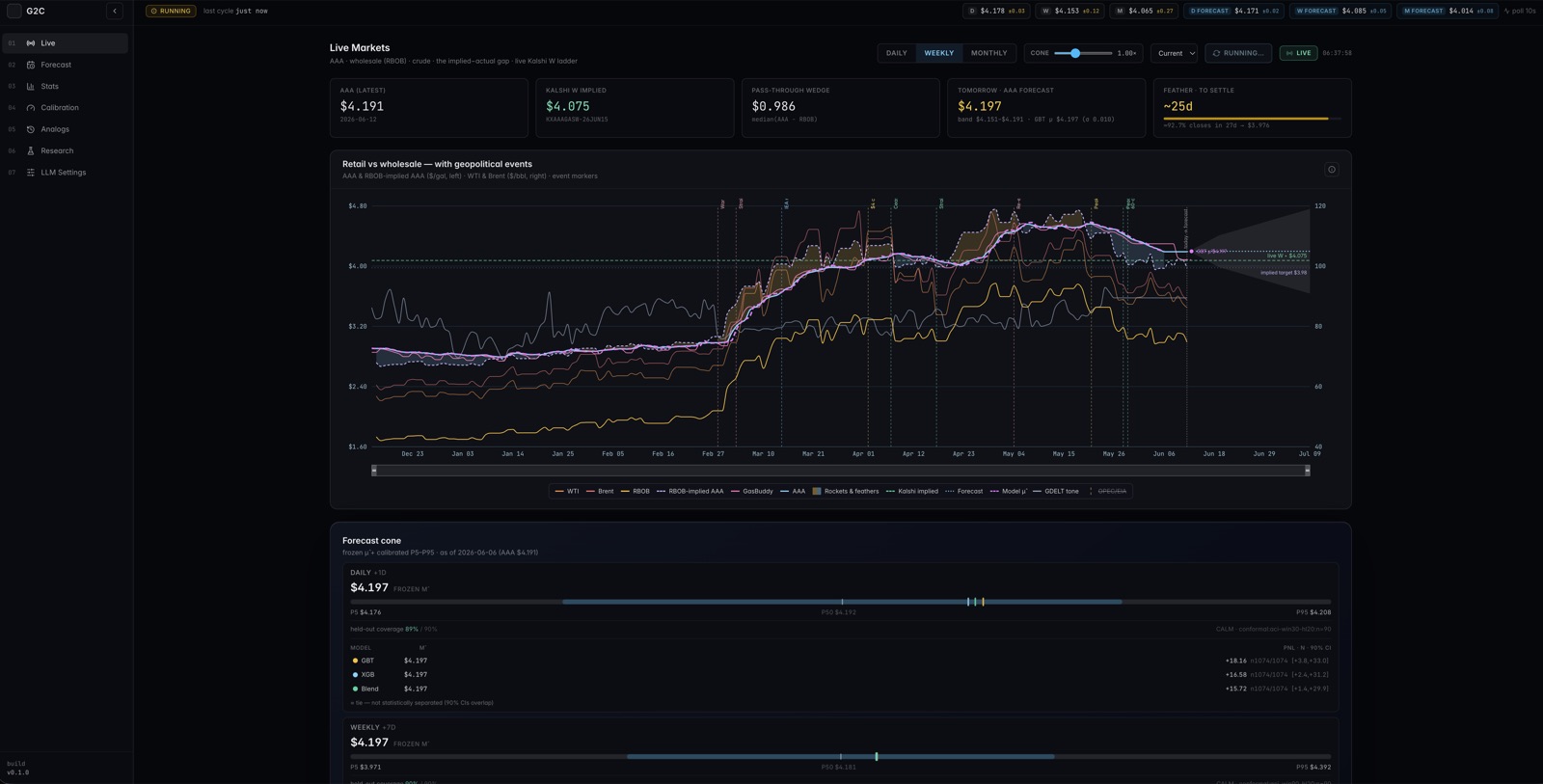
A young market plus public leading data — the one setting where a solo researcher could plausibly have an edge.
In March 2026, Kalshi launched daily prediction markets on the AAA national gasoline price — contracts that pay $1 if the price crosses a threshold. The market was weeks old and thin, and the underlying number has known leading indicators: GasBuddy's crowdsourced prices lead the AAA survey by days, and wholesale gasoline futures lead it by about a week. So I framed it as a falsifiable hypothesis and committed to a rule before writing a line of code: measure, don't trade. The system would never place a live trade or hold a funded account until the data proved an edge existed. Over May and June 2026 — 220 commits — I built the platform to answer one question honestly.
02 / An end-to-end platform, not a notebook
Roughly 150k lines of Python, ~20k of TypeScript, ~1,290 tests.
It is a real system: roughly 150,000 lines of Python across 479 files, ~20,000 lines of TypeScript, and ~1,290 automated tests. The architecture is pluggable — five abstract contracts (DataFeed, Model, Broker, Strategy, Notifier) wired together by YAML config via dotted import paths, so every component swaps without touching the core. Ten-plus automated feeds pull free public data: AAA and GasBuddy prices, RBOB/WTI/Brent futures with proxy fallback, EIA weekly petroleum reports, FRED, GDELT geopolitical news tone, NOAA hurricane tracking, the OPEC calendar, and Kalshi's order books. Everything lands in a single SQLite audit trail — runs, feed snapshots, predictions, recommendations, outcomes — joinable end to end. The pipeline is deliberately decoupled: collect touches the network; predict runs DB-only and is fully reproducible. A read-only FastAPI layer serves a React 19 + TypeScript dashboard with 12 routes, its API types code-generated from the OpenAPI schema.
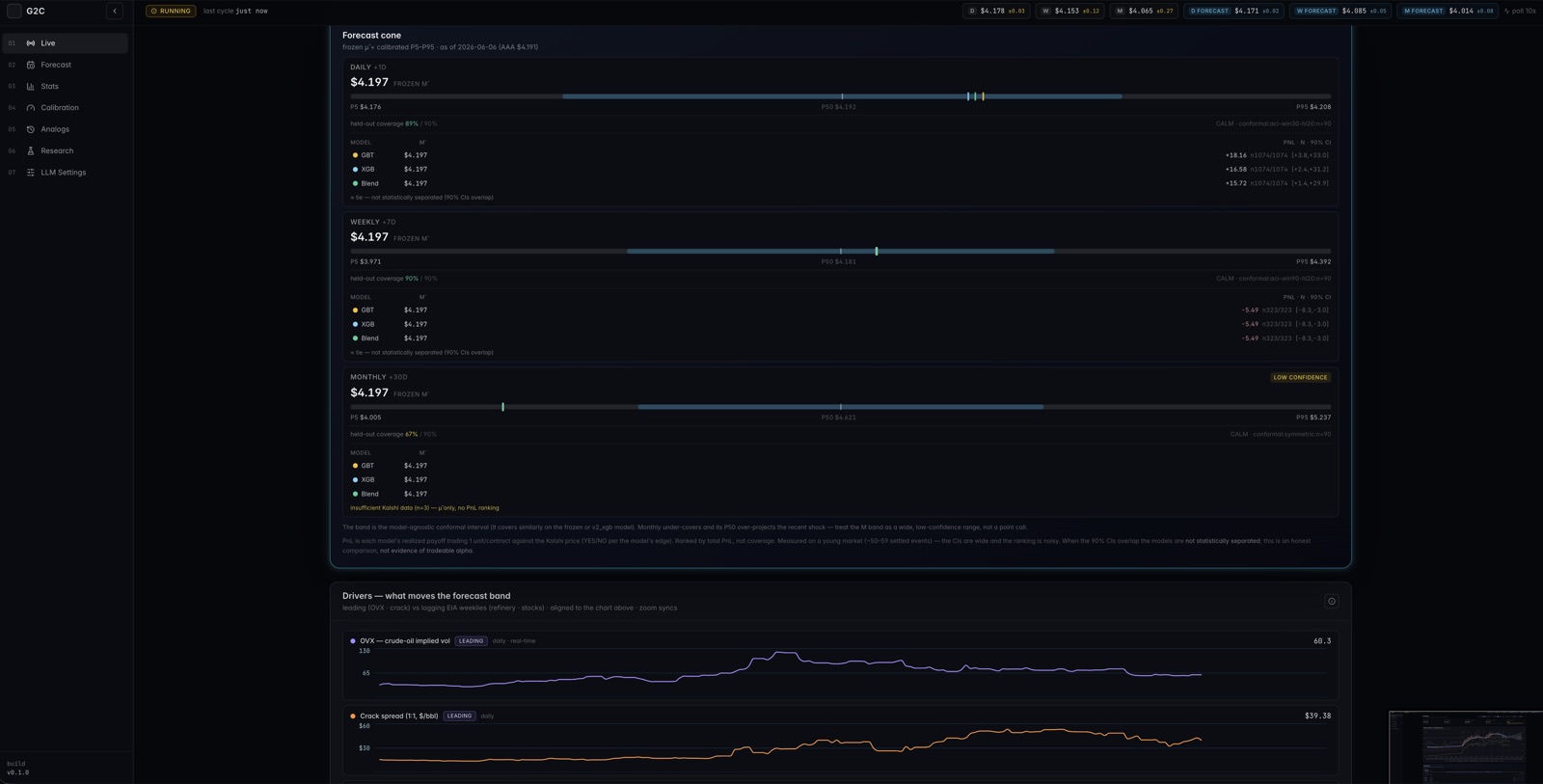
03 / Forecasting in a small-data regime
About 700 daily training rows — which makes leakage the number-one threat.
The modeling constraint was brutal: about 700 daily training rows. That rules out bigger models and makes leakage the number-one threat. I built three model generations and selected by walk-forward bake-off — a hand-built AR(1) + pass-through model with regime-dependent volatility, then gradient-boosted trees (the primary), then an XGBoost variant with tiered feature sets. The uncertainty got more care than the point forecast: an adaptive conformal inference cone self-corrects its width daily, and empirical coverage improved from 0.827 to 0.899 on the daily horizon and 0.814 to 0.895 weekly, against a 0.90 target — with the monthly horizon honestly reported as under-covering. Every forecast ships with exact Shapley-value explanations: with nine features, all 2⁹ coalitions are enumerated exactly, no approximation library required.
04 / The bugs that mattered
Two look-ahead leaks nearly poisoned the research.
My third-generation model looked about 15% better than everything else — until a feature audit found it was peeking at the future; the fix erased the advantage. The second leak was subtler: a feature partially derived from the target itself. Both were caught by process, not luck. The most valuable bug came out of a "failed" experiment: a permutation-test harness built to check whether news tone predicted volatility instead revealed that my σ calibration was wrong — prediction intervals were roughly 3.3× too narrow. Fixing that corrected the most important number in the system: the one that tells you how much you don't know. This is exactly what the test suite, the audit-trail database, and the pre-registered methodology were there to catch.
05 / LLM features engineered, not bolted on
Three Claude API integrations, each wired into the audit trail like any other component.
A news parser turns raw headlines into structured geopolitical risk signals — Iran, Hormuz, supply disruptions — that feed the models as data. A dashboard AI advisor reads the day's full model state — forecast, conformal cone, live market prices — and produces an assessment; its system prompt is engineered with an efficient-market prior and coherence checks, so it argues against overconfidence instead of amplifying it. And a closed-loop hyperparameter tuner: the LLM proposes XGBoost parameter changes, the system applies and evaluates them, one button in the UI. The design rule throughout: an LLM component must be observable, testable, and disposable if it doesn't earn its keep.
06 / The verdict: no edge — with proof
Statistically detectable, economically meaningless, below fees.
Three findings closed the thesis. The edge was too small. Point-forecast skill over a competent benchmark was ~+3% at horizon 1 — roughly 0.1 cents per gallon. Not alpha. The market out-forecast the model. My forecasts "beat" the Kalshi price only in the first ~90 minutes after a market opened — not executably — and by settlement the market was ~4× more accurate. Adverse selection killed execution. Simulated passive limit orders filled only 23% of the time, with a fill-selection gap of about −18¢ per contract: profitable if everything filled, net negative on actual fills. The vivid version — near-certain contracts settled YES 91% as a group, but among those whose ask actually dropped to a $0.30 lowball bid, only 33% did. The cheap fill is the bad news arriving. Walk-forward only, block bootstrap by event date, permutation tests, pre-registered kill criteria, formal postmortem.
07 / What a null result proves
The platform never traded a dollar — by design.
The platform's job was to answer "is there an edge?" before money was at risk, and it answered no, with evidence. Most people learn adverse selection with their wallet; this system learned it from data, and the conclusion is documented in a formal postmortem. The transferable skills are concrete: reliable data pipelines built from messy public sources, ML with honest calibrated uncertainty instead of overconfident point guesses, full-stack delivery from SQLite schema to React dashboard, and LLM integrations engineered with priors and evaluation loops rather than bolted on. But the differentiator is the discipline: pre-registered criteria, leakage audits, and the willingness to report what the data actually says — even when it kills the exciting hypothesis. An engineer who will falsify his own thesis won't oversell yours.
08 / The system, end to end
Ten-plus feeds land in one audited store; calibrated models feed a dashboard and a closed LLM loop.
Want this level of rigor on your data problem? Code walkthrough available on request — get in touch.